
''Fin'' des cookies tiers : quelle efficacité pour la vie privée ?
Beaucoup de solutions publicitaires visant à pallier la disparition prochaine des cookies tiers émergent. Critique sur l'ensemble de ces solutions.
Publié le 23 mars 2024, mis à jour le 25 avril 2024
Le contexte
En avril 2020, Google a annoncé vouloir supprimer les cookies tiers de son navigateur Chrome avec la mise en oeuvre de sa "Privacy Sandbox". La mise en application de cette décision connaît beaucoup de retard et d'embûches, mais devrait malgré tout se concrétiser vers la fin de cette année.
Mise à jour au 25 avril : Google a annoncé le 23 avril mettre en oeuvre la "dépraciation des cookies tiers" début 2025 désormais.
Une fois mise en place, c'est tout un pan de l'Adtech qui va devoir s'adapter. Certaines d'entre elles l'ont soit déjà fait, soit sont en train d'anticiper cette perspective. Beaucoup de commentaires ont été émis sur ces solutions dites "cookiekess", mais toujours sous un même angle d'approche : celui du marché.
Aussi avons-nous décidé de décrire et apprécier, de notre point de vue cette fois-ci, ces solutions. Mais tout d'abord, un rappel sur ce que sont les cookies tiers et ce à quoi ils servent.
Cookies tiers et cookies de première partie
Beaucoup de descriptions ont été faites au sujet des cookies. Pour le lecteur pour lequel ces notions demeurent floues, nous allons prendre une exemple concret pour tenter d'illustrer le propos.
Un Internaute se rend sur le site "lemonde.fr" et accepte les cookies. S'il souhaite les lister (Si quelques Internautes se posent la question de savoir comment faire pour lister les cookies sur un site, nous fournissons une courte méthode en fin d'article via ce lien), il pourra observer, parmi les caractéristiques des cookies, le nom de domaine qui leur est associé. La plupart des cookies ont un nom de domaine associé soit à "lemonde.fr", soit "www.lemonde.fr" (encadré en vert sur notre exemple).
Ce sont des cookies dits "de première partie". Qu'est-ce que cela signifie ?
- Que l'éditeur du "Monde" a décidé et autorisé l'écriture de ces cookies,
- Qu'il a connaissance de leur écriture sur le terminal de l'utilisateur,
- Que seul l'éditeur du domaine "lemonde.fr" y a un accès originel. (Nous employons ce terme "originel" car l'éditeur peut, s'il le souhaite, transmettre l'information contenue par le cookie à des domaines qui ne sont pas le sien, i.e. des domaines tiers). En tout état de cause, il a la maîtrise technique du dépôt et du traitement ultérieur éventuel de ce cookie.
D'autres cookies, (exemple encadré en rouge sur la capture d'écran ci-dessous), n'ont pas le même nom de domaine que celui de l'éditeur. Qu'est-ce que cela implique ?
- Que l'éditeur du "Monde" n'a pas toujours connaissance du dépôt de ces cookies,
- Qu'une fois en place sur le terminal de l'usager et jusqu'à effacement de celui-ci, ce cookie peut être lu par n'importe quel domaine qui y a accès. Dans notre cas, Outbrain pourra lire les informations contenues par le cookie sur des sites ultérieurs visités.
Il est essentiel de comprendre que lorsqu'on parle de la fin des cookies, ou lorsqu'on évoque un monde "post-cookies", on ne parle QUE des cookies tiers et non de première partie qu'il n'est pas question de supprimer.

Que permet(tait) le cookie tiers ?
Les organismes publicitaires déposant des cookies tiers peuvent suivre la navigation de l'internaute et son comportement. C'est surtout en cela que le cookie tiers constitue une atteinte majeure à la vie privée des usagers.
Néanmoins il est tout de même important de préciser que pour l'Adtech, il ne permet pas que cela. Si le profilage de l'utilisateur que nous ne cessons de déplorer constitue une activité importante pour les organismes publicitaires, il faut savoir qu'il y a plus important encore à leurs yeux : la mesure, qui permet d'estimer l'efficacité et la rentabilité d'une campagne publicitaire. Ainsi, pour prendre un exemple, le cookie tiers permet de compter le nombre d'affichage d'une publicité sur chaque site, et le nombre de fois où l'usager y a été exposé. On définit par voie de conséquence un "capping", c'est-à-dire une limite du nombre d'impressions d'une même publicité vue par un utilisateur, afin d'éviter que celle-ci ne devienne contre productive. La mesure est fondamentale pour l'Adtech car elle permet, entre autres et de façon indirecte, de facturer.
On rappelle ici que d'ores et déjà, beaucoup de navigateurs n'acceptent plus les cookies tiers, soit dans leur configuration par défaut (ce qui est le cas de Edge), soit de façon "native" et définitive. Chrome est l'un, si ce n'est le dernier navigateur à leur fermer la porte. Cependant, dans la mesure où il demeure très majoritaire quant à son utilisation, beaucoup d'Adtech ont continué à se reposer sur cette technologie.
D'autres, en revanche, proposent des solutions alternatives. Nous allons décrire ces solutions dites "Cookieless". La description sera faite par catégorie de méthode utilisée, avec plus de détail pour chaque catégorie et surtout, avec notre appréciation sur l'impact en termes de vie privée pour l'uilisateur, le tout résumé par un code couleur pour chaque Adtech abordée, figurant dans un tableau synthétique.
Le paysage Cookieless
Nicolas Jaimes, journaliste chez Mntd, a rédigé un très bon article sur le sujet que vous pouvez consulter sur cette page (attention, lien avec traceurs). Cet particle réalise une cartographie des solutions en place et en décrit l'analyse et les perspectives, vues par l'Adtech évidemment. On y retrouve notamment un tableau qui récapitule les principales solutions cookieless utilisées par les principaux éditeurs, médias en particulier.
Voici donc les catégories de méthode employée.
1 - L'identifiant partagé
ID5 et LiveRamp
Chaque cookie de première partie a une valeur différente pour chaque site visité et chaque navigateur. L'une des solutions consiste donc pour certains organismes à identifier le terminal de l'utilisateur, voire l'utilisateur lui-même, par d'autres moyens que le cookie et attribuer un identifiant qui sera distribué à tout éditeur de site qui interrogera la base de données de l'organisme.
A cette fin, toute donnée relative à l'utilisateur ou son terminal est utilisée : e-mail hashé, numéro de téléphone hashé, adresse IP, user agent de l'utilisateur, etc. Cette collecte de données se réalise par l'éditeur du site lui-même, qui les transmet à l'organisme. Un exemple avec la société ID5, qui explique aux éditeurs par le menu sur sur cette page la manière de transmettre vos données personnelles. Et si cela ne plaît pas trop à l'éditeur, qu'à cela ne tienne : il reste le tracking server side. Morceau choisi de la page évoquée en lien, édifiant.

La difficulté initiale pour ce type d'organisme consiste à monter une base de données utilisateur suffisamment grande pour que la réconciliation (ou synchronisation) des données collectées et la redistribution d'un identifiant unique soient possible. Avec les cookies tiers, le suivi de navigation et les fingerprints réalisés pendant des années, ces sociétés n'ont désormais aucune difficulté à relier un terminal à un identifiant. Pour donner une idée au lecteur, la société ID5 possède "environ" 2 milliards et demi d'indentifiants, comme l'indique le "Guide Cookieless 2022" édité par l'IAB, dont nous fournissons ici un extrait
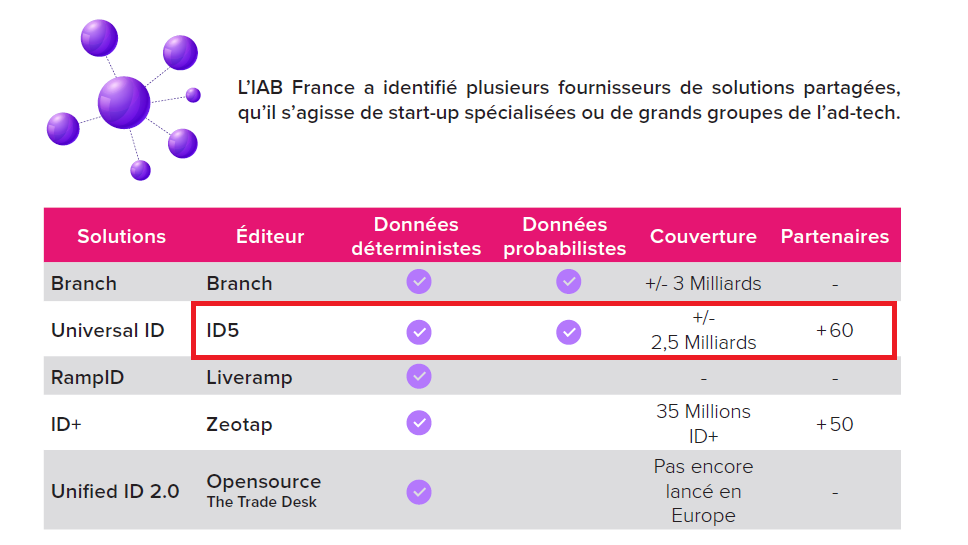
On aura compris qu'en termes de vie privée, l'utilisation de ce type de solutions est d'une certaine manière pire que le cookie tiers, parce que bien moins décelable. Et ceci d'autant plus que, si le consentement est requis et globalement respecté pour l'utilisation de telles solutions, il existe certains cas où ce consentement est contourné. D'autres sociétés, pires qu'ID5 (!), n'utilisent que des données propres à l'individu pour réaliser la même chose. En tête de liste : LiveRamp, avec son Ramp ID. Rappel sur le caractère parfois totalement non conforme de certaines de ses méthodes.
Nous avons l'année dernière dénoncé le transfert d'e-mail hashé par certains éditeurs vers des organismes tiers à l'occasion de création de compte. Si les réseaux sociaux en font partie (notamment Pinterest, champion en la matière, Tiktok et Meta), c'est également le cas de LiveRamp. En effet, certains éditeurs, après REFUS des traceurs par l'utilisateur, et à l'occasion de la création d'un compte, transmettent (possiblement sans le savoir, parce qu'on a préconisé à l'éditeur de déployer une balise "telle quelle") les données de formulaire sous format hashé (généralement SHA 256) AVANT MEME que l'usager ne valide les éléments, parfois en captant les lettres touche par touche sur clavier, parfois en transmettant le contenu d'un champ de formulaire lorsque l'utilisateur clique sur le champ suivant (et donc pas encore sur "OK").
Autant dire que ces méthodes, exploitées par LiveRamp pour lequel on évoque une "Data clean room" (nous n'avons pas la même notion de propreté...), ont permis à cette Adtech de monter à travers la planète une gigantesque base de donnée utilisateur, exploitée, revendue, etc...
Wolfie Christl dénonce pour sa part, dans un remarquable rapport téléchargeable sur cette page de son site "Crakedlabs", une exploitation opaque et démesurée de ces données. Suite à ce rapport, deux plaintes ont été déposées à l'encontre de LiveRamp : une en Grande-Bretagne et une en France.
Gravity
Une autre solution consiste pour plusieurs sites à intégrer une alliance. Celle-ci, avec l'accord des éditeurs, peut donc via ceux-ci réaliser un tracking sur les sites membres et un suivi comportemental. Encore faut-il que cette alliance soit suffisamment vaste pour que les données recueillies soient significatives. C'est notamment le cas de Gravity, dont nous avons déjà longuement parlé dans deux de nos articles précédents ici et là.
On comprendra que le pot commun de traceurs de première partie élaboré par l'ensemble des éditeurs ne fait que remplacer le cookie tiers. En termes de collecte de données personnelles, le résultat est strictement le même pour les usagers.
On se contentera de rappeler ici que le volume de données est gigantesque, et qu'un doute subsiste quant aux capacités de ré identification des individus, comme nous l'avons longuement évoqué. En tout état de cause, Gravity ne fait absolument aucun cas des droits des usagers : nous avons formulé une demande d'accès laissée sans aucune réponse de sa part, et deux réclamation CNIL en ce sens. Malgré un rappel à l'ordre de notre APD (c'est du moins ce que la CNIL nous a indiqué), Gravity continue de mépriser notre demande de droit d'accès.
First ID : les bonnes vielles méthodes
Dans le même esprit, mais avec une technique différente, nous vous présentons First-ID, le petit poucet qui grandit très vite et a eu le mérite (unique) de sentir la perspective.
First ID met en oeuvre ce que nous appelons pour notre part un "cookie tiers déguisé en cookie première partie", avec une méthode plutôt ancienne et classique : le bounce tracking. Explications.
Lorsqu'un utilisateur réalise un achat ligne, il est fréquemment redirigé vers une page de paiement sécurisée. Une fois le paiement réalisé, l'acheteur est de nouveau redirigé vers la page d'origine, avec en surplus un traceur (qui peut être un cookie, tout-à-fait licite au demeurant) précisant que le paiement a été correctement réalisé. Le traceur est, dans cette configuration, techniquement considéré comme de première partie.
First ID fait la même chose. Lorsque vous acceptez les traceurs sur un site l'ayant pour partenaire, vous êtes redirigiés vers le "site-portail" de First ID, qui dépose tranquilou un identifiant sur votre terminal, puis vous redirige tout aussi tranquilou vers le site visité, avec un magnifique cookie qui sera considéré comme de première partie. Exemple avec le site "marieclaire.fr", réalisé sur le navigateur Chrome :

précision d'ordre chronologique : dans un premier temps, le cookie est déposé par le domaine "firstid.fr" (Mention "1" entourée), et seul ce cookie apparaît, le temps d'être redirigé vers le domaine initial "marieclaire.fr". Puis ce même cookie apparaît avec cette fois-ci le domaine initial associé (entouré en "2" sur la capture d'écran).
Point d'importance : cette "technologie" ne se met en place qu'avec le consentement explicite de l'Internaute. Sur l'ensemble des sites que nous avons audités, hormis d'éventuels Darkpatterns liés à la CMP (i.e. la "cookie banner"), nous n'avons pas décelé d'écriture non conforme, et ce point est important en terme de respect du choix de l'Internaute.
Par ailleurs, ce type de technologie est assez facilement détectable par les Adblockers. Une synthèse sur ce point est proposée par notre toujours pointu Pixeldetracking sur cette page. La performance d'une telle technologie est donc directement liée à :
- D'une part, l'acceptation de traceurs par l'Internaute,
- D'autre part, l'absence d'Adblocker sur le navigateur.
Un cas plus intéressant : UTIQ
A l'origine, UTIQ était loin d'avoir une considération positive de notre part. La raison en était simple : l'idée était de créer un identifiant persistant via une alliance d'opérateurs téléphoniques. Mais en creusant la technologie, nous devons reconnaître que des efforts sensibles ont été consentis sur le sujet, pour plusieurs raisons. Avant de les détailler, précisons tout de même qu'un profilage utilisateur est, avec consentement, réalisé comme toute autre Adtech à l'occasion de visites de sites dont UTIQ est partenaire.
En revanche (Et très certainement parce que ce type de technologie était de nature à créer de grosses difficultés en termes de vie privée), UTIQ a insisté sur le consentement, au point qu'en cas d'acceptation de traceurs à l'arrivée d'un site, une deuxième fenêtre de consentement s'affiche. Celle-ci est spécifique à UTIQ, avec un choix simple et effectif : Accepter ou refuser. Un accès à un "consenthub" est par ailleurs disponible pour récapituler les choix de l'Internaute. L'usager peut y définir ses choix de façon granulaire, site par site.

Réaliser une deuxième fenêtre de consentement spécifique était un pari risqué, notamment en termes de fatigue au consentement, mais il semble réussir.
D'autre part, la technologie en elle-même est de nature moins volatile en termes de données personnelles. On pourrait parler d'un système en "double aveugle" : l'identifiant généré par l'opérateur téléphonique de l'usager est le seul identifiant connu par UTIQ, qui envoie alors aux partenaires deux valeurs différentes de l'identifiant, appelés "pass". Ainsi, il n'y a pas d'indentifiant partagé permettant de relier opérateurs téléphoniques et chaîne programmatique.
En revanche, comme nous l'avons dit, UTIQ se fonde malgré tout sur des données déterministes, à des fins de segmentation. Le problème de fond qui peut se poser à terme est le suivant : si UTIQ possède un volume de données significatif, quid des capacités de ré-identification et/ou de réconciliation de profil "avec des moyens raisonnables", en environnement loggué par exemple (i.e. lorsqu'un usager est connecté à un compte)?
Car le lecteur l'aura compris, pour toute Adtech, la difficulté majeure en termes de vie privée ne réside pas dans l'attribution d'un identifiant, mais dans la possibilité de lier cet identifiant à une personne, que cela soit ou non volontaire. A titre d'exemple, pour prendre le cas de Meta, la récupération d'email hashé est à l'origine voulue pour obtenir un identifiant identique quel que soit le canal utilisé. Mais lorsqu'on détient cinq milliards d'adresses email (non hashées, celles-ci), il est tout-à-fait réalisable de faire correspondre ceux-ci aux identifiants reçus.
Ainsi, en première intention, on peut considérer que la ré-identification d'une personne via la technologie de UTIQ demeure plus complexe que pour les Adtech précédemment citées.
2 - Les solutions contextuelles
Celles-ci sont beaucoup plus plaisantes à nos yeux dans la mesure où la collecte de données personnelles y est nettement moindre. Nous avons rédigé il y a quelques mois un article sur le sujet qui en explique le fonctionnement. Pour résumer, la publicité contextuelle s'appuie essentiellement sur la nature de la page visitée, et non sur le visiteur.
Ce type de publicité est complexe à mettre en place. Tout d'abord, parce qu'il faut repérer et définir les pages web existantes, et donc d'une certaine manière, il est nécessaire de "scrapper" un très grand nombre de pages. Ensuite, si certains sites peuvent naturellement amener une publicité contextuelle par leur nature, d'autres en revanche peuvent poser des difficultés de ciblage. A titre d'exemple, on comprendra qu'il peut être pertinent d'imprimer des pubs pour casseroles sur un site de recettes de cuisine, mais il est moins certain qu'un Internaute recherche des articles de mécanique auto s'il prend rendez-vous en ligne chez un garagiste qui monétise son site pour faire réparer son véhicule. Par ailleurs, de façon générale, le contextuel a longtemps été boudé par absence de rentabilité.
Aussi, pour pallier ces difficultés, beaucoup d'Adtech contextuelles sont tout de même amenées à réaliser un profilage. La nette différence avec les Adtech programmatiques est que ce profilage n'est pas réalisé sur l'individu en temps réel, mais a déjà été réalisé en amont sur une population type consentante. On comprendra qu'une base de données comportementale de départ est donc nécessaire pour réaliser du contextuel "rentable", rares sont les Adtech contextuelles "pures". Plusieurs méthodes ont été appliquées pour arriver à ce modèle. Nous allons les détailler, en citant certaines d'entres elles.
Les petits malins : Ogury
Stratégie mise en place dès le départ ou saisie d'opportunité ? On a tendance à opter pour la première version. Ogury a été fondée en 2014, et est passée en solution contextuelle en 2018. Pour ce faire, la start-up a construit sa base de données en réalisant d'une part de la segmentation avec consentement, et d'autre part via des sondages. Disposant en 2018 d'une base de données suffisamment solide, elle a pu basculer en solution contextuelle tout en se fondant sur les profils qu'elle a éloborés, c'est pourquoi elle évoque elle-même des "personas" et non des "personnes", au même titre qu'elle évoque une "personification" au lieu d'une "personalisation" de publicité. En auditant les sites, on observe en effet qu'Ogury collecte peu de données personnelles, dont l'objectif du reste "ne consiste qu'à" réaliser des enchères.
Pour l'anecdote, il est amusant de constater que l'actuel COO d'Ogury était l'ex DG de la branche Retail Media de.... Criteo. L'intéressé aurait-il viré sa cutie de confidentialité ? (a prendre pour tous les lecteurs comme une taquinerie et non comme une provocation !).
Les méticuleux : Implct.
Nous renvoyons le lecteur à notre article sur le sujet concernant cette Adtech. En bref, Implcit est une solution que nous avons clairement tendance à apprécier. A relever, pour le détail, une mise à jour de l'article de Nicolas James : Implcit semble avoir conclu un accord ou une expérimentation avec le Figaro, qui déploie cette solution sur son site.
Les vrais-faux contextuels : Weborama et MediaSquare
Ogury et Implct ont d'emblée pris une voie à contre-courant de ce qui se faisait au moment de leur création, ce qui n'est pas le cas des Adtechs dont nous allons parler.
On commence par Weborama. Si sa solution contextuelle baptisée Goldenfish semble intéressante en soi, il faut savoir que fondamentalement, Weborama est une grande plateforme de données (DMP : Data Managment Platform), qui les collecte à la volée via cookies tiers et qui sert également de plateforme de données client de première partie (Customer Data Platform : CDP). Globalement et très schématiquement, elle réalise la même chose que Médiarithmics, sur lequel nous nous sommes largement étendus dans un récent article consultable sur cette page.
Le moins que l'on puisse dire est que de la data, Weborama en a. La DMP, qui utilisait jusqu'alors des méthodes classiques de tracking et de collecte de données, a développé en 2021 sa solution contextuelle, qui se fonde sur sa masse de données associée à une intelligence artificielle dite sémantique. Ce qui nous gêne profondément, c'est que l'utilisation de Goldenfish par Weborama n'est pas exclusive : pour le moment, "Webo" déploie ses solutions contextuelles comme programmatiques et on émet de forts doutes sur le fait qu'a terme, Weborama mute en solution contextuelle exclusive.
Mediasquare, pour sa part. est une association d'éditeurs qui optimisent leur inventaire publicitaire. Nous pouvons faire des observations analogues à Weborama : la co existence de solutions programmatiques et contextuelles font que pour ces deux Adtechs, le passage au contextuel se fait plutôt à marche forcée et ne répond pas à une réelle aspiration au respect de la vie privée des Internautes.
3 - Les solutions de mesure d'attention
Nous sommes très partagés sur ce type de solutions, potentiellement très intrusives. Ces solutions, comme Xpln par exemple, mesurent la façon dont sont vues les annonces par l'utilisateur : temps d'exposition, vue partielle ou complète, etc. Cependant, elles mesurent également certaines actions de l'Internaute comme les scrolls, par exemple. Si ce type de solution semble à priori ne s'attacher qu'à l'impression publicitaire en elle-même, elle demeure de nature à se comporter comme une solution analytique comportementale parfois poussée.
En revanche, nous n'avons pas à ce stade mis en lumière un quelconque traçage de l'usager : Xpln semble se concentrer sur la seule impression publicitaire.
Synthèse
Voici un tableau synthétique de nos évaluations (forcément partiales) des solutions que nous venons d'évoquer.
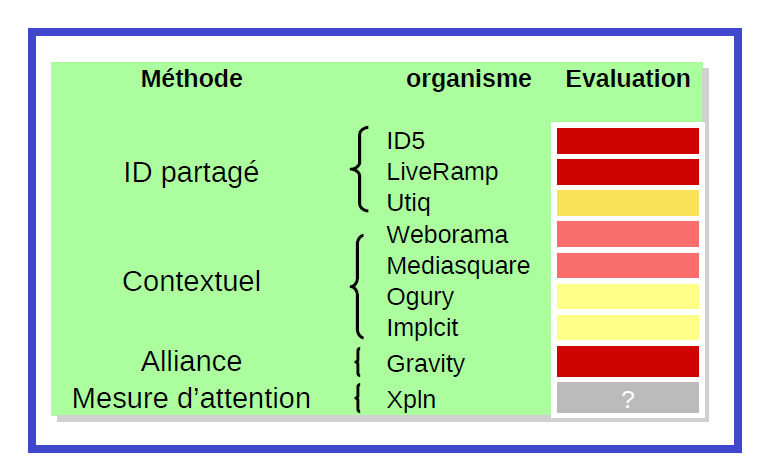
Qu'en retenir ?
Que cela ne change rien pour l'utilisateur.
Nous venons de décrire certaines solutions plus ou moins délétères ou vertueuses en termes de vie privée. Comme chacun peut s'en douter, il en existe bien d'autres, parfois très intrusives. Or, chaque gros éditeur, pour sa part, a dans une grande majorité des cas des centaines de partenaires, comptant seulement une poignée de solutions cookieless à ce stade. Si donc quelques solutions plus vertueuses sont présentes çà et là (et nous venons de voir qu'elles sont loin de toutes l'être), l'internaute qui visite un site sera forcément confronté à des Adtechs aux technologies classiques (pas de cookies mais des pixels de suivi par exemple, ou fingerprint etc.). Ainsi donc, vu de l'utilisateur, les améliorations en termes de vie privée ne sont présentes qu'à la marge. La Privacy Sandbox de Google, si elle est de nature à faire bouger les lignes (et ceci sans compter les difficultés liées à d'éventuels abus de position dominante regardées de très près par l'autorité de la concurrence britannique, la CMA), ne change que très peu de choses sur le fond.
Dignilog.
Annexe : comment voir un cookie
Faire un click droit sur une zone "neutre" de la page visitée. Dérouler le menu pour cliquer sur "inspecter". Le débugger du navigateur s'ouvre.

Cliquer sur l'onglet "application" (s'il n'apparaît pas, cliquer sur les deux chevrons à droite), et dérouler l'onglet cookie. La liste des cookies apparaît.

©Dignilog 2024, tous droits réservés
A propos Politique de confidentialité
Contact : contact@dignilog.com
twitter : @Dignilog1 mastodon : @Dignilog@pouet.chapril.org
Pascal VAUTRIN
Lien :?
Réagissez, commentez !
- Aucun commentaire pour l'instant